

Expertise Data Science : Comment réussir son initiative Big Data ?
Publié le dans seminar-past
Séminaire du Mastère Spécialisé® Big Data du 18 février 2016 avec Emmanuel Manceau, manager chez Quantmetry et Ysé Wanono, diplômée du Mastère Spécialisé, consultante chez Quantmetry.
Le secteur du numérique, et particulièrement le traitement de données, est extrêmement demandé en entreprise. Tenir un discours pointu sur les enjeux de la data sicence est donc devenu nécessaire. Le rôle de Quantmetry est d’expliquer la manière dont se déroulent les sujets de data science en entreprises, les initiatives et le développement des projets autour de la donnée qui nécessitent un système de pilotage extrêmement complet. Emmanuel Manceau, manager chez Quantmetry et Ysé Wanono, diplômée du Mastère Spécialisé Big Data et consultante chez Quantmetry sont venus présenter les clés de la réussite d’un projet Big Data mais également les risques qu’un tel projet peut présenter.
Réussir un projet Big Data
Nous arrivons actuellement dans une phase où les entreprises attendent des résultats concrets grâce à l’analyse des données à travers des projets forts. Pourtant, les entreprises capables de réussir un projet data science sont peu nombreuses. La plupart des projets commencés sont un échec, notamment imputable à un manque d’expérience dans ce domaine. De plus, d’après les facteurs de risque du « Standish Group », les projets Big Data cumulent pratiquement tous les facteurs de risques des projets informatiques : manque de « user input », des exigences et spécifications incomplètes, manque de support exécutif, de compétences technologiques, exigences non réalistes… Le problème majeur étant que les exigences ne sont, souvent, pas définies. A cela s’ajoute le fait que 50% des résultats du projet ne sont pas montrables au client.
Réussir un projet pilote
Un projet data science est un cycle itératif et progressif qui se déroule principalement en 3 étapes :
- Compréhension du métier et des données
- Phase de préparation des données et test de quelques hypothèses (50% des charges du projet, aucun résultat montrable)
- Phase d’évaluation et modélisation du modèle. Certains résultats de l’évaluation du modèle peuvent conduire à créer une nouvelle boucle d’itération afin de revoir les hypothèses initiales et pivoter.
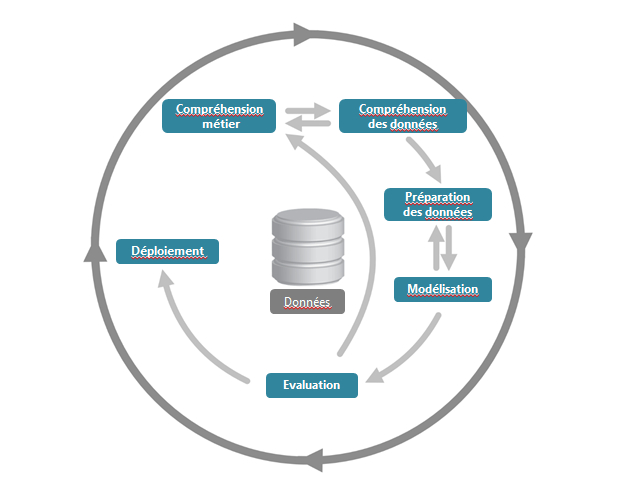
En pratique, un projet Big Data démarre souvent sur des objectifs flous et imprécis. C’est pourquoi il est important, en début de projet, de voir avec le client les hypothèses à tester et de faire le cadrage des hypothèses qualitatives recherchées. Même si la définition de chaque partie de pivot à lieu en amont du projet avec le client, il sera toujours possible de pivoter en cours de projet afin de redéfinir les objectifs initiaux et d’ajuster le périmètre.
Il est important de ne pas avoir une vision trop macroscopique et détachée du relationnel. Il est parfois nécessaire de revenir à un algorithme simple tel que des arbres de décision pour déterminer la cause du problème et il est primordial de s’adapter à la situation quitte à laisser de côté la dimension prédictive.
Très peu de groupes sont capables de faire des modèles de prédiction et d’en sortir des applications viables pour l’entreprise. Par exemple, de grands groupes tels que Facebook ou Google n’ont aucun problème à mettre à libre disposition leurs algorithmes car leur véritable atout est la façon dont ils manipulent ces algorithmes pour en faire un produit. L’enjeu actuel est donc : Comment aller en production à partir des analyses que l’on a faites ?
Les phases d’un projet de data science
Un projet de data science suit le tunnel caractéristique des projets innovants. En forme d’entonnoir, il affine, jette et avorte des initiatives au cours du temps. Ce tunnel est jalonné d’étapes (go – no go) nécessaires pour savoir si le projet vaut le coup de continuer ou s’il vaut mieux arrêter. A chacune de ces étapes, il est important de définir avec le client ce qui conditionne l’arrêt ou le maintien du projet.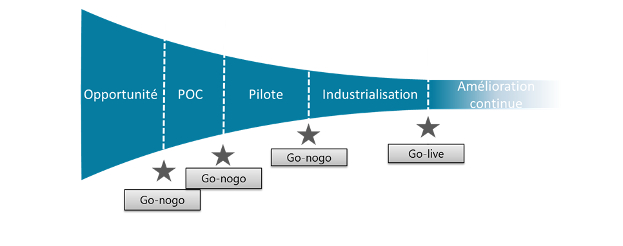
Les principaux risques et facteurs de succès selon Quantmetry
Principaux risques :
- Ne pas investir du temps avec les opérationnels
- Négliger la validation par l’expérience
- Confondre modèle de « data scientist » et « application informatique »
- Généraliser trop vite les résultats d’un modèle
- Ne pas questionner la vérité des données
- S’enfermer dans une voie sans issue
Principaux facteurs clés de succès :
- S’assurer de l’implication des opérationnels
- Investir dans la compréhension métier
- Passer du temps à comprendre et nettoyer les données
- Adopter une démarche itérative et progressive
- Donner des critères de faisabilité et valider des étapes de go/no go projet
- Ajuster les objectifs et le périmètre en cours de projet et pivoter si nécessaire
- Définir précisément la cible