

Data Science « Haute couture » ou « Prêt à porter » ?
Publié le dans seminar-past
 Compte-rendu de l'intervention du 20 octobre 2016 au cours du séminaire du Mastère Spécialisé® Big Data.
Compte-rendu de l'intervention du 20 octobre 2016 au cours du séminaire du Mastère Spécialisé® Big Data.
Après avoir travaillé au sein d’une start-up pendant une dizaine d’années, Christophe Bourguignat a sentir venir la vague du Big Data et s’est formé au machine learning, notamment avec le MOOC de Coursera puis avec des challenges Kaggle. Il a ensuite intégré le Data Innovation Lab d’Axa pendant deux ans, avant de créer sa start-up, Zelros, en décembre 2015. Zelros a pour vocation d’être le trait d’union entre les data scientists « frustrés de voir que leur projet ne passe pas en production » et les métiers en attente des avancées promises par les data sciences.
La data science qui se pratique lors des challenges de type Kaggle, ou la data science académique, diffère largement de la data science d’entreprise : au point qu’on pourrait les comparer respectivement à de la haute couture et à du prêt à porter. Cette dualité qui oppose machine learning de concours et machine learning en vie réelle n’est pas nouvelle, elle mérite cependant que l’on s’y attarde.
L’interprétation des modèles et l’adhésion des métiers
Le data scientist peut se retrouver fréquemment face à un rejet de ses modèles prédictifs par les métiers de l’entreprise, car ces derniers ont du mal à faire confiance à ce qu’ils perçoivent comme une boite noire. Et ce, d’autant plus que les modèles les plus précis sont, en général, les moins interprétables.
Le Conseil d’Etat recommande d’imposer une obligation de transparence sur les données personnelles utilisées par un algorithme, ainsi que sur le raisonnement général de celui-ci. Mais un algorithme peut combiner des dizaines de modèles, rendant très difficile de donner cet « aperçu général ». Il existe cependant plusieurs façons d’apporter des éclaircissements et de montrer aux métiers et aux managers que l’on maîtrise l’algorithme et qu’on ne le subit pas.
Les variables prises en compte peuvent avoir un rôle plus ou moins important dans le résultat final, il est tout à fait possible de faire ressortir les variables qui ont été principalement utilisées par le modèle pour prendre ses décisions.
On peut également s’intéresser aux seuils de décision, en « dépliant » l’arbre décisionnel (random forest) et en regardant, à chaque nœud, quel est le seuil où chaque paramètre va faire basculer le choix d’un côté ou de l’autre. On peut alors faire des statistiques sur chaque paramètre et rendre visible les seuils de bascule.
L’intuition métier, qui consiste par exemple à se dire que le prix de location d’une chambre devrait être plus élevé pendant la période d’un festival, peut être prise en compte et forcée dans le modèle. L’algorithme doit alors respecter les contraintes imposées par le « prior belief » (a priori), en l’occurrence augmenter les prix au cours d’une certaine période, indépendamment de ce qu’il aurait déterminé d’après le modèle. Ainsi, même si le modèle est complexe et inexplicable, on peut garder la main sur une partie du processus.
La frontière peut être floue entre le data scientist qui établit son modèle mathématique et l’envoie au métier, et ce dernier qui attend des explications complémentaires de la part du data scientist. Ce dernier doit donc être prêt à aller plus loin dans les explications…
Jusqu’à présent, nous avons essayé de comprendre le modèle de façon macro. Mais la question type des métiers va être de savoir : pourquoi l’algorithme donne-t-il ce résultat ? Ce client risque de résilier son abonnement, mais pour quelle raison : est-il mécontent du service, change-t-il de tranche d’âge ?... En effet deux personnes ayant le même indice élevé de « churn » ne l’ont pas forcément pour les mêmes raisons, il faut donc pouvoir expliquer échantillon par échantillon.
On peut alors s’intéresser à la feature contribution (contribution des paramètres). Il s’agit de parcourir le chemin de l’arbre décisionnel en sens inverse et essayer de comprendre comment on affine la prédiction. Dans le cas de l’estimation du prix d’un appartement (exemple du dataset des appartements de Boston), on part d’un prix moyen et chaque nœud amène une inflexion en plus ou en moins du prix initial. Cela est rendu possible depuis mars 2015, quand Scikit Learn a permis de stocker les valeurs intermédiaires calculées dans l’arbre décisionnel.
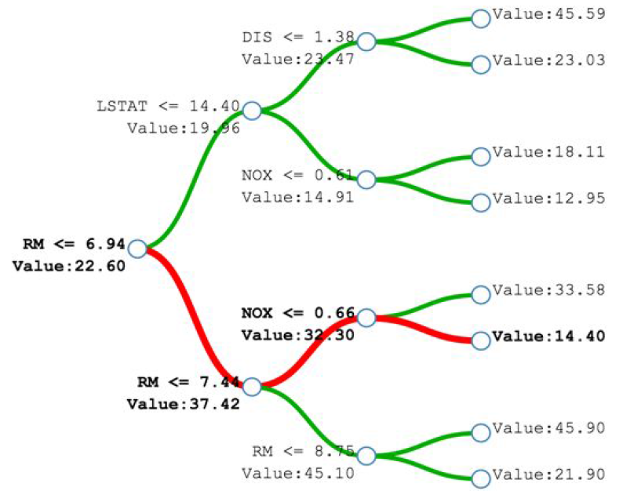
Si « prédire c’est se tromper », l’analyse du degré d’erreur est un sujet intéressant, pour indiquer d’une part que l’on est conscient qu’on peut se tromper et d’autre part, d’évaluer le niveau de cette erreur. On peut par exemple établir une moyenne des prédictions de chaque arbre, tout en conservant les valeurs minimales et maximales. On pourra ainsi constater que plus la prédiction est proche de la vérité, moins la marge d’erreur est grande. Cela permet de distinguer deux prédictions apparemment similaire mais dont l’une aura un intervalle de confiance plus élevé.
L’étude de l’interdépendance des paramètres permet de voir si, toutes choses égales par ailleurs, une variable en particulier impacte la prédiction. Ainsi, on peut faire une simulation où le prix, la durée, etc., varie et voir si cela impact ou non le résultat final. Si diminuer le prix d’un service montre une diminution significative de l’attrition, alors les métiers peuvent prendre cette information en considération.
Enfin, la transparence est un outil précieux pour emporter l’adhésion des métiers. On peut distinguer trois niveaux : l’accès aux données brutes, mais qui ne donne pas la compréhension du modèle ; l’accès aux paramètres du modèles, dont la compréhension reste l’apanage de spécialistes ; enfin la création d’une application reposant sur le modèle afin que chacun puisse agir sur les paramètres et voir le résultat. En définitive, le meilleur moyen de s’assurer la confiance des métiers est de montrer que l’on maîtrise le modèle.
Quelques aspects de la mise en production des modèles
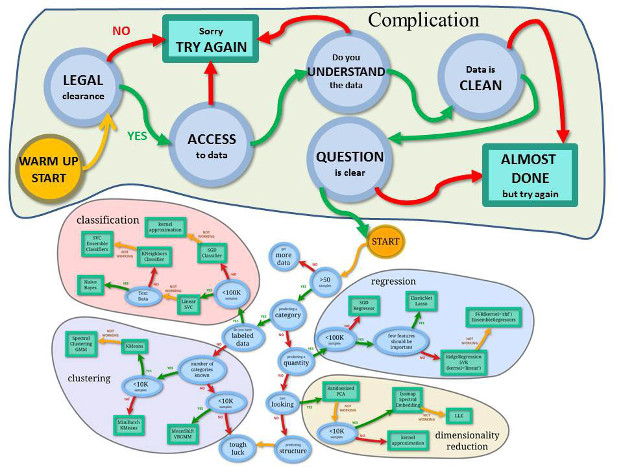
La « cheat sheet » de Scikit Learn, bien connue des data scientists, comprend les étapes classification, clustering, régression et réduction de dimensionalités. On pourrait y ajouter une étape préalable : la complication… Il faut en effet commencer par résoudre les problèmes légaux concernant l’utilisation des données (données personnelles, lieu d’hébergement et règlementation afférente…), résoudre la question de l’accès à ces données, s’assurer de leur bonne compréhension ainsi que de leur qualité et enfin, poser clairement la question à laquelle on souhaite répondre…
Au sein d’un département BI traditionnel on trouvait des profils de Data Analysts (Tableau Sofware…), ingénieurs (extraction des données, datawarehouse…), administrateurs de bases de données (gestion de l’infrastructure). Aujourd’hui les rôles ont changé, et on trouve le Business, les Data Scientist, les Data engineers et les Software engineers. Ce quatre catégories sont encore trop étanches. En effet il n’est pas envisageable que le data scientist travaille seul sur un modèle, puis le confie au software engineer qui n’aurait plus qu’à le coder. Chacun doit avoir une vision globale du sujet.
Il faudra également se poser prochainement la question de la maintenance des modèles. Certains paramètres, au fil du temps, vont se déprécier et ne seront plus utilisés, encombrant alors inutilement et ralentissant l’exécution de l’algorithme. Il se peut aussi qu’un algorithme se serve des prédictions d’un autre modèle non maintenu : ses résultats seront alors faussés…
Quelques écueils récurrents lors du déploiement des modèles : les données récupérées en entrée ne sont pas celles attendues, le workflow doit être réécrit pour s’adapter aux systèmes de l’entreprise (avec les risques que cela comporte), les données utilisées lors de la conception du modèle ne sont plus maintenues par l’entreprise, difficulté d’effectuer une cross validation sur un flux de données réelles…
En conclusion, le travail du data scientist en entreprise peut être très différent de celui des challenges, avec des cas d’usage moins variés et des données répétitives. A l’inverse, celui des challenges (Kaggle ou autres) repose sur des conditions très éloignées du « monde réel ». Il est pourtant essentiel pour permettre aux data scientists de s’ouvrir l’esprit, d’expérimenter des approches différentes et de découvrir de nouvelles façons de traiter un sujet. Prêt à porter et haute couture sont donc indissociables dans la vie du data scientist !
Pour aller plus loin