

Alkemics, du sémantique pour la grande distribution
Publié le dans seminar-past
Séminaire du Mastère Spécialisé Big Data du jeudi 21 avril 2016, avec Antoine Perrin, co-founder & CTO d’Alkemics, et Pierre Arbelet, data scientist et diplômé du Mastère Spécialisé® Big Data.
![]()
Lors de sa première intervention au Mastère Spécialisé® Big Data, il y a un an et demi, Alkemics proposait une DMP (Data Management Plaform) à usages multiples. La jeune pousse se composait alors de 12 personnes. Depuis l’entreprise a grandi et emploie 52 personnes en France.
Il a fallu intégrer 35 personnes en l’espace de sept mois. Alekmics a veillé à recruter des profils juniors et seniors, tout en conservant l’état d’esprit, la culture start-up. Une telle croissance impacte beaucoup de choses en termes de communication, de procédures… La société est par exemple passée d’une à cinq équipes de développeurs, qui travaillent selon des sprints agiles en Scrum.
Le but d’Alkemics est de collecter et structurer la donnée pour permettre aux marques et aux acteurs de la grande distribution d’exploiter des « données produit » ou des « données utilisateur » de la meilleure qualité possible. La donnée produit est en effet la pierre angulaire du retail : la marque la créé, le distributeur la vend et le consommateur la consomme.
Pour la grande distribution, les enjeux sont multiples : il y a de plus en plus de produits, la gestion logistique est plus complexe, l’affluence dans les grandes surfaces peut se mesurer en temps réel, les canaux de vente sont aussi plus nombreux… Enfin, de nouveaux acteurs comme Amazon, originaire du e-commerce, s’intéressent au retail traditionnel.
Collecter et structurer la donnée avec Product Stream
Product Stream est une plateforme qui permet aux marques et distributeurs de collaborer, autour de la donnée, pour optimiser le marketing et les ventes. Traditionnellement, une marque et une enseigne qui ont des enjeux sur différentes équipes (vendeurs, marketing, logistique, qualité…), travaillent avec des technologies différentes et au sein de silos séparés.
Alkemics propose une centralisation du canal de gestion de la donnée en mettant le produit au milieu des différents SI. La donnée est structurée pour obtenir des attributs normalisés. Au lieu de voir trois produits différents identifiés par un code barre, on peut avoir des centaines d’attributs sur chaque produit (marque, ingrédients, conditionnement, format…). Cette base de données centralisée permet aussi de communiquer avec d’autres partenaires, comme Google Product Listing Ads.

Product Stream permet de lister l’ensemble des produits, de les filtrer par marque, par caractéristiques… Pour chaque produit, il y a plusieurs champs correspondants aux attributs ontologiques pertinents. La plateforme normalise automatiquement les ingrédients à partir du champ texte de composition. À cela s’ajoutent des informations médias : visuels, recette, tutoriels, vidéos… On retrouve ensuite sur les sites des distributeurs des fiches produits dont le contenu est directement fourni par la plateforme d’Alkemics.
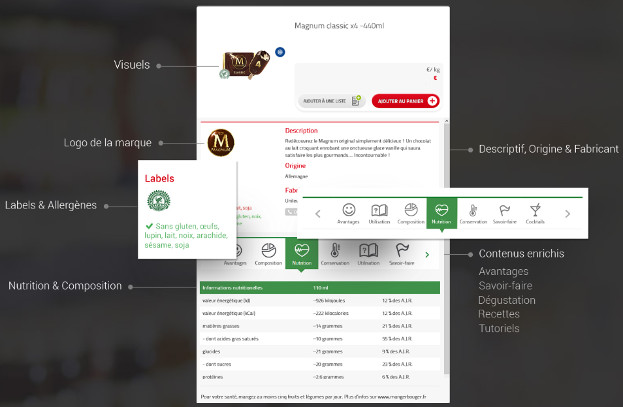
Exemple de fiche produit
Naissance d’une ontologie
Initialement, la technologie d’Alkemics avait pour but la compréhension automatisée de recettes à partir de sites de recettes tels que Marmiton.org, pour permettre l’affichage puis l’achat des produits correspondants d’une enseigne. L’enjeu était de comprendre de façon automatisée le langage des internautes qui rédigent les fiches recettes (natural language processing). Pour passer d’un ingrédient (par exemple, « lait ») à des produits, une ontologie a été construite en associant des descripteurs tels que : blanc, vache, liquide, bouteille, brique, lactose, caséine, Candia, Lactel…
Actuellement, ce qu’un distributeur voit sur un ticket de caisse est une inscription de 40 caractères (HPP GR MK ORG BT 6X25CL FR). Avec l’ontologie d’Alkemics, on peut décrypter ce code : GRMK : growing milk (lait de croissance), ORG : organic (biologique), 6x25CL : pack de 6 ¼ de litre… On peut en déduire ensuite le client cible (ici, un foyer avec bébé).
L’ontologie a été construite manuellement au début puis enrichie de façon automatique pour représenter l’ensemble des concepts dans un domaine, d’abord alimentaire, puis de grande consommation. Cinq personnes travaillent à temps plein sur ce modèle, pour qu’il soit à la fois suffisamment concret pour être efficace et suffisamment abstrait pour avoir de la puissance. Cette ontologie peut être décrite à la fois comme un graphe ou un arbre.
A cause des enjeux de guerre des prix, il y a dans la grande distribution un renouvellement des codes barre. 40% des produits sont ainsi « nouveaux » chaque année. En faisant des analyses sur des produits qui changent de 40% tous les ans, on peut avoir l’impression que la consommation d’un client change de 40% alors que son comportement est inchangé.
Le chaînage produit est une réponse à cette difficulté. Il permet de faire des liens entre des produits similaires voir identiques (par exemple Coca Cola, Pepsi Cola, cola de distributeur, Coca Zéro… en bouteilles en ou cannettes… en 1,5 litres ou 33 cL, par packs de 4 ou de 6, en promotion ou non…) Cela permet aussi d’assurer la cohérence entre des codes-barres qui sont différents selon les sites de production (15 usines en Europe pour Coca Cola). En cas de rupture de stock, cela permet également de proposer les produits de substitution les plus pertinents par rapport au produit souhaité, en se basant sur des attributs très fins du produit.
Technologies mises en œuvre
Si l’approche initiale d’Alkemics a été de se reposer sur une technologie unique, elle a été tempérée par l’intérêt d’avoir des outils conçus spécialement pour telle ou telle application spécifique. Le système a été construit brique par brique, en s’assurant après chaque itération que tout était cohérent. C’est en effet un enjeu à part entière que d’assurer la cohérence entre tous ces systèmes entre lesquels les interactions sont nombreuses :
- Datacenter Cloud : Microsoft Azure
- Applications Web: Python, Golang
- Backend Web: Percona, Couchbase, Elasticsearch, Cassandra
- Analytics : Cassandra (time series), Hadoop (Hortonworks), Spark
- Message queue : RabbitMQ
- Monitoring : Grafana, DataDog, Nagios
En backoffice, trois outils permettent de s’assurer du bon fonctionnement de la plateforme.
Luigi est une solution open source en Python développée par Spotify pour gérer des flux multiples et complexes, il est utilisé comme moteur de workflow et lance des tâches dépendantes les unes des autres. DataDog récupère des informations systèmes et applicatifs. Enfin, Grafana permet d’avoir un monitoring visuel sur l’évolution des timeseries produites par les traitements d’analyse.
Activer les données
Il est possible de segmenter l’audience à partir des données de transaction (les tickets de caisse). En effet, 75% en valeur des transactions sont liées à une carte de fidélité. Alkemics propose donc aux distributeurs de segmenter une audience qui correspond à leur brief marketing, pour cibler des consommateurs sur le Web en « real time bidding (RTB)». Les mêmes mécanismes permettent d’analyser a posteriori les ventes du distributeur, pour voir si la population ciblée a changé de comportement. Il est ensuite possible de profiter de reportings en temps réel des taux de transformation, taux de clic… et transactions passées en magasin.
Du point de vue de la Data Science
L’approche d’Alkemics soulève énormément de challenges du point de vue de la science des données, à partir des données produits et des données de transaction : prédiction de churn, recommandation, prédiction d’assortiments pour optimiser les marges sans perdre de vente, targeting, détection d’anomalies, advertising pur : optimisation de stratégie (apprentissage par renforcement), attribution multi-touch (montant du ROI final qu’on attribue à chacun des canaux), chainage produit, prédiction d’affluence, prédictions de ventes… Le churn est un cas d’école.
Le churn (ou attrition en français) est le fait qu’un client n’utilise plus une solution. Pour une entreprise, cela coûte beaucoup plus cher de perdre un client fidèle que de faire l’acquisition d’un nouveau client. Si le travail sur des données labellisées est connu, comment envisager le churn dans un contexte non régit par un contrat (type abonnement), par exemple si un client cesse de venir dans un magasin ? Que peut-on alors prédire et comment ?
La première phase consiste à trouver une définition du churn dans ce contexte et à labelliser les données. On peut par exemple définir le « churner » comme une personne qui dépense 30% de moins que ce qu’elle a dépensé durant un trimestre de référence pendant les trois trimestres suivants, ou encore comme une personne qui ne vient plus du tout. La seconde phase demande de trouver les modèles qui vont correspondre à des cas très fortement déséquilibrés, représentant 3 à 5% de l’ensemble des données. Ces modèles peuvent être par exemple : logistic regression, random forests, extremely randomized trees, gradient boosting trees, multivariate adaptive regression splines, modèles bayésiens…
Cela coûte également beaucoup plus cher de mal classifier un churner que de mal classifier une personne qui n’en est pas un. Le taux de vrais positifs est alors plus important que la précision. Le choix des métriques est alors primordial. L’objectif est donc de minimiser le nombre de personnes qu’on va contacter dans une campagne marketing, tout en maximisant le nombre de churners qu’on va toucher via cette campagne. La pertinence des modèles peut être enfin évaluée par le biais de modélisations de retours sur investissements.